

 English
English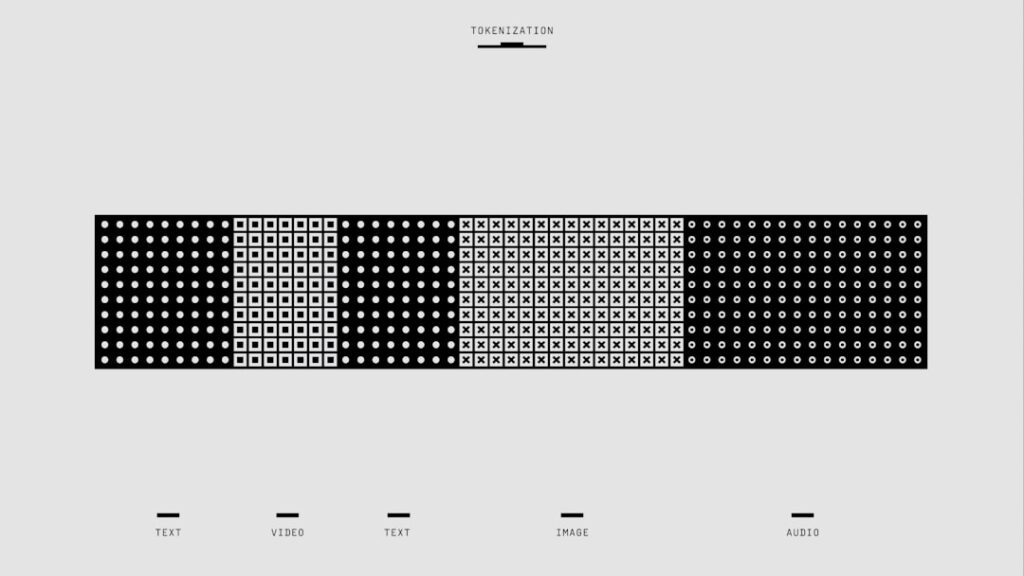
يناير
الذكاء الصناعي
بيانات التدريب: التحدي الأكبر أمام جودة نماذج الذكاء الاصطناعي في 2026
تعتبر بيانات التدريب من العناصر الأساسية في تطوير نماذج الذكاء الاصطناعي. فهي تمثل الأساس الذي يعتمد عليه الذكاء الاصطناعي لتعلم الأنماط واتخاذ القرارات. في ظل التقدم السريع في مجالات مثل التعلم العميق والتعلم الآلي، أصبحت الحاجة إلى بيانات تدريب دقيقة وموثوقة أكثر إلحاحًا. فبدون بيانات كافية، قد تواجه النماذج صعوبات في التعرف على الأنماط أو تقديم نتائج دقيقة، مما يؤثر سلبًا على الأداء العام.
تتزايد أهمية بيانات التدريب مع تزايد التطبيقات العملية للذكاء الاصطناعي في مجالات متعددة، مثل الرعاية الصحية، والتمويل، والتجارة الإلكترونية. فكلما زادت دقة البيانات وجودتها، زادت قدرة النماذج على تقديم نتائج موثوقة. لذا، فإن التركيز على تحسين جودة بيانات التدريب يعد أمرًا حيويًا لضمان نجاح تطبيقات الذكاء الاصطناعي.
ملخص
- بيانات التدريب أساسية لتحسين أداء نماذج الذكاء الاصطناعي وجودتها.
- تواجه عملية جمع بيانات تدريب كافية تحديات كبيرة تتعلق بالجودة والكمية.
- تنظيف وتحسين بيانات التدريب يعزز دقة وكفاءة النماذج الذكية.
- نقص بيانات التدريب يؤثر سلباً على قدرة النماذج على التعلم والتعميم.
- دعم الحكومات والشركات والتشريعات المناسبة ضروريان لضمان جودة بيانات التدريب المستقبلية.
أهمية بيانات التدريب في تحسين جودة النماذج الذكاء الاصطناعي
تلعب بيانات التدريب دورًا محوريًا في تحسين جودة نماذج الذكاء الاصطناعي. فالنماذج التي تتلقى بيانات تدريب غنية ومتنوعة تكون أكثر قدرة على التعلم والتكيف مع الظروف المختلفة. على سبيل المثال، في مجال التعرف على الصور، يمكن أن تؤدي مجموعة بيانات متنوعة تشمل صورًا من زوايا وإضاءة مختلفة إلى تحسين دقة النموذج بشكل كبير. هذا التنوع يساعد النموذج على فهم الأنماط بشكل أفضل وتقديم نتائج أكثر دقة.
علاوة على ذلك، فإن جودة البيانات تؤثر بشكل مباشر على قدرة النموذج على التعميم. إذا كانت بيانات التدريب تحتوي على تحيزات أو أخطاء، فإن النموذج قد يتعلم هذه الأخطاء ويطبقها في مواقف جديدة، مما يؤدي إلى نتائج غير دقيقة. لذلك، من الضروري أن تكون بيانات التدريب خالية من التحيزات وأن تعكس الواقع بشكل صحيح لضمان أداء جيد للنماذج.
تحديات توفير بيانات التدريب الكافية وذات الجودة العالية

تواجه المؤسسات العديد من التحديات عند محاولة توفير بيانات تدريب كافية وذات جودة عالية. أولاً، قد يكون جمع البيانات عملية مكلفة وتستغرق وقتًا طويلاً. يتطلب الأمر موارد بشرية وتقنية لجمع البيانات وتنظيفها وتحليلها. بالإضافة إلى ذلك، قد تكون بعض البيانات حساسة أو محمية بموجب قوانين الخصوصية، مما يزيد من تعقيد عملية جمعها.
ثانيًا، قد تكون البيانات المتاحة غير كافية أو غير متنوعة. في بعض المجالات، مثل الرعاية الصحية، قد يكون من الصعب الحصول على بيانات تمثل جميع الفئات السكانية أو الحالات المرضية. هذا النقص في التنوع يمكن أن يؤدي إلى نماذج غير دقيقة وغير قادرة على التعامل مع مجموعة واسعة من السيناريوهات. لذا، فإن التحديات المتعلقة بتوفير بيانات تدريب ذات جودة عالية تتطلب استراتيجيات مبتكرة وفعالة.
استراتيجيات لتحسين جودة بيانات التدريب وتنظيفها
هناك عدة استراتيجيات يمكن اعتمادها لتحسين جودة بيانات التدريب وتنظيفها. أولاً، يجب أن تتضمن عملية جمع البيانات خطوات واضحة لضمان دقتها وموثوقيتها. يمكن استخدام تقنيات مثل التحقق من صحة البيانات والتدقيق لضمان أن البيانات التي يتم جمعها تعكس الواقع بشكل صحيح.
ثانيًا، يمكن استخدام أدوات وتقنيات لتنظيف البيانات وإزالة الأخطاء والتحيزات. تشمل هذه الأدوات تقنيات التعلم الآلي التي يمكن أن تساعد في تحديد الأنماط غير المرغوب فيها أو القيم الشاذة في البيانات. بالإضافة إلى ذلك، يمكن أن تسهم عمليات المراجعة البشرية في تحسين جودة البيانات من خلال فحصها وتقييمها بشكل دوري.
تأثير نقص بيانات التدريب على جودة النماذج الذكاء الاصطناعي
يمكن أن يكون لنقص بيانات التدريب تأثير كبير على جودة نماذج الذكاء الاصطناعي. عندما تكون البيانات غير كافية، قد تواجه النماذج صعوبة في التعرف على الأنماط أو اتخاذ قرارات دقيقة. هذا النقص يمكن أن يؤدي إلى نتائج غير موثوقة ويقلل من فعالية التطبيقات العملية للذكاء الاصطناعي.
علاوة على ذلك، يمكن أن يؤدي نقص البيانات إلى تحيزات في النماذج. إذا كانت البيانات التي تم استخدامها لتدريب النموذج تمثل مجموعة معينة فقط، فقد يتعلم النموذج التحيزات الموجودة في تلك البيانات ويطبقها في مواقف جديدة. هذا يمكن أن يكون له عواقب وخيمة، خاصة في المجالات الحساسة مثل الرعاية الصحية أو العدالة الجنائية.
أفضل الممارسات في جمع واستخدام بيانات التدريب
تتضمن أفضل الممارسات في جمع واستخدام بيانات التدريب عدة خطوات أساسية. أولاً، يجب تحديد الأهداف بوضوح قبل بدء عملية جمع البيانات. يساعد ذلك في توجيه الجهود نحو جمع البيانات الأكثر صلة بالموضوع المطلوب دراسته أو النموذج المراد تطويره.
ثانيًا، ينبغي استخدام مصادر متعددة لجمع البيانات لضمان تنوعها وشموليتها. يمكن أن تشمل هذه المصادر البيانات العامة، والمسوحات، والتعاون مع مؤسسات أخرى لجمع بيانات إضافية. كما يجب أن تتضمن عملية جمع البيانات آليات للتحقق من جودتها وموثوقيتها.
تطوير تقنيات جديدة لتعويض نقص بيانات التدريب
في ظل التحديات المرتبطة بنقص بيانات التدريب، يتم تطوير تقنيات جديدة لتعويض هذا النقص. واحدة من هذه التقنيات هي استخدام التعلم المعزز، حيث يمكن للنماذج التعلم من التجارب بدلاً من الاعتماد فقط على البيانات المجمعة مسبقًا. هذا النوع من التعلم يمكن أن يساعد في تحسين أداء النماذج حتى عندما تكون البيانات المتاحة محدودة.
بالإضافة إلى ذلك، يتم استكشاف تقنيات مثل توليد البيانات الاصطناعية باستخدام الشبكات العصبية التوليدية (GANs). هذه التقنيات تسمح بإنشاء بيانات جديدة تشبه البيانات الأصلية، مما يساعد في زيادة حجم مجموعة البيانات وتحسين تنوعها. هذه الابتكارات تمثل خطوات مهمة نحو التغلب على نقص بيانات التدريب.
دور الحكومات والشركات في دعم توفير بيانات التدريب الكافية
تلعب الحكومات والشركات دورًا حيويًا في دعم توفير بيانات التدريب الكافية. يمكن للحكومات أن تسهم من خلال وضع سياسات تشجع على تبادل البيانات بين المؤسسات وتوفير التمويل للمشاريع التي تهدف إلى جمع وتحليل البيانات. كما يمكن أن تساعد التشريعات في حماية الخصوصية وضمان استخدام البيانات بشكل مسؤول.
من جهة أخرى، يمكن للشركات الاستثمار في تطوير منصات لجمع البيانات وتحليلها بشكل فعال. التعاون بين الشركات والمؤسسات الأكاديمية يمكن أن يسهم أيضًا في تحسين جودة البيانات المتاحة وتوسيع نطاق استخدامها. هذا التعاون يمكن أن يؤدي إلى تطوير نماذج أكثر دقة وفعالية.
تأثير القوانين والتشريعات على جودة بيانات التدريب
تؤثر القوانين والتشريعات بشكل كبير على جودة بيانات التدريب المتاحة للاستخدام. قوانين حماية الخصوصية مثل اللائحة العامة لحماية البيانات (GDPR) في الاتحاد الأوروبي تفرض قيودًا صارمة على كيفية جمع واستخدام البيانات الشخصية. هذه القيود تهدف إلى حماية حقوق الأفراد ولكنها قد تؤثر أيضًا على قدرة المؤسسات على جمع بيانات تدريب كافية.
علاوة على ذلك، فإن التشريعات المتعلقة بحقوق الملكية الفكرية قد تؤثر أيضًا على إمكانية الوصول إلى مجموعات البيانات الكبيرة التي قد تكون ضرورية لتدريب نماذج الذكاء الاصطناعي. لذا، فإن التوازن بين حماية الخصوصية وحقوق الملكية الفكرية وبين الحاجة إلى بيانات تدريب فعالة يعد أمرًا معقدًا يتطلب اهتمامًا خاصًا من صانعي السياسات.
توقعات لتطور جودة بيانات التدريب في المستقبل
من المتوقع أن تتطور جودة بيانات التدريب بشكل ملحوظ في المستقبل بفضل الابتكارات التكنولوجية والتقدم في مجالات الذكاء الاصطناعي وتحليل البيانات. ستساهم التقنيات الجديدة مثل التعلم العميق والشبكات العصبية المتقدمة في تحسين طرق جمع وتحليل البيانات، مما يؤدي إلى تحسين جودتها وموثوقيتها.
كما يُتوقع أن تزداد أهمية التعاون بين المؤسسات الأكاديمية والصناعية والحكومية لتطوير استراتيجيات فعالة لجمع البيانات وتحسين جودتها. هذا التعاون يمكن أن يسهم في إنشاء قواعد بيانات شاملة ومتنوعة تدعم تطوير نماذج ذكاء اصطناعي أكثر دقة وفعالية.
خلاصة: أهمية التركيز على تحسين بيانات التدريب لتطوير نماذج الذكاء الاصطناعي في 2026
في الختام، يتضح أن تحسين جودة بيانات التدريب يعد أمرًا حيويًا لتطوير نماذج الذكاء الاصطناعي الفعالة والدقيقة بحلول عام 2026 وما بعده. تواجه المؤسسات تحديات متعددة تتعلق بجمع وتوفير بيانات تدريب كافية وذات جودة عالية، ولكن هناك استراتيجيات وتقنيات جديدة يمكن اعتمادها للتغلب على هذه التحديات.
إن التعاون بين الحكومات والشركات والمجتمع الأكاديمي سيكون له تأثير كبير على تحسين جودة بيانات التدريب المتاحة للاستخدام. لذا، يجب أن يكون التركيز مستمرًا على تطوير سياسات واستراتيجيات تدعم هذا الهدف لضمان نجاح تطبيقات الذكاء الاصطناعي وتحقيق الفوائد المرجوة منها.